
正規表現を覚えると、パソコンを使った各種の作業が捗る(はかどる)。
プログラミング、データ集計、EXCEL、WORDなどのオフィス作業などなど、何でも応用できる。
ワテも正規表現をいつ覚えたのか忘れたが、かなり昔に覚えた。
確か UNIX を勉強中に、grep、sed、awk などのコマンドやスクリプトを書く時に一緒に覚えたと思う。
とは言っても、正規表現の全文法を完全に理解している訳ではなく、単純な文字列の検索や置換が出来る程度の知識だ。
最近になって、肯定先読み、否定先読み、肯定戻り読み、否定戻り読みなども覚えたので、それによって応用範囲が広がった。
でも、正規表現は奥が深いので、ワテが知らない書き方がまだまだあると思う。
と言う事で、全10回くらいのシリーズで正規表現入門を書きたい。
世に中には、そのようなサイトは山ほどあるので、ここでは多くの実例を元にワテ流の実践的な記事を書きたいと思う。
では本題に入ろう。
正規表現入門の第一回目例題
では、早速、第一回目の例題をやってみよう。
以下のように、一行に人名が沢山ありそれらが / で区切られている。
近藤真彦 / 東山紀之 / TOKIO / KinKi Kids / タッキー&翼 / NEWS / 関ジャニ∞ / KAT-TUN / Hey! Say! JUMP(京セラドームより中継出演) / Kis-My-Ft2 / Sexy Zone / A.B.C-Z / 中山優馬 / ジャニーズWEST
これを整形して、
近藤真彦 東山紀之 TOKIO KinKi Kids タッキー&翼 NEWS 関ジャニ∞ KAT-TUN Hey! Say! JUMP(京セラドームより中継出演) Kis-My-Ft2 Sexy Zone A.B.C-Z 中山優馬 ジャニーズWEST
のように複数行に分離して、かつ、前後の空白やスラッシュを取り除きたい。
普通なら、メモ帳にでも貼り付けて、ひたすらマウスとキーボード操作で改行や削除を繰り返す手順となる。
上記の例のように人名が十数人程度ならそれでも可能だ。
でも例えば、上記のような行が何千行もあるとなると、そんな手法では到底無理だろう。
こういう時に正規表現なら、一発で出来る。
でも、いきなり一発でやるのは難しいので、数発くらいでやってみたい。
正規表現を使える環境を準備する
まず、正規表現を使える環境の準備が必要だ。
ワテが思いつくのは、以下の通り。
エディタの機能に正規表現があるもの
notepad++
サクラエディタ
秀丸エディタ
Visual Studio
Cygwin(シグウィン)などで、Windows上にUNIXライクな環境を構築
Cygwin(シグウィン)は、Windows上にUNIXライクな環境を構築出来るオープンソースなフリーソフトだ。
手軽にUnix環境を構築出来るので、Cygwinはお勧めだ。
そうすればviエディタも使える。
正規表現が使えるWEBサイトを使う
オンライン正規表現データ変換 (ワテも作ってみた)
などである。
ワテは、今回の例のようにちょっとしたデータ整形をしたい場合には、 notepad++ を良く使う。フリーソフトのエディタでは高性能で使い易いと思う。
勿論、Visual Studio の環境もお勧めだ。
Visual Studio の環境で実行してみよう
さて、ここでは Visual Studio の環境で実行してみよう。
適当なテキストファイルを新規作成して、そこに文字列を貼り付ける。
近藤真彦 / 東山紀之 / TOKIO / KinKi Kids / タッキー&翼 / NEWS / 関ジャニ∞ / KAT-TUN / Hey! Say! JUMP(京セラドームより中継出演) / Kis-My-Ft2 / Sexy Zone / A.B.C-Z / 中山優馬 / ジャニーズWEST
実際の Visual Studio の画面は以下のようになる。
検索と置換ダイアログの置換機能が表示されている。
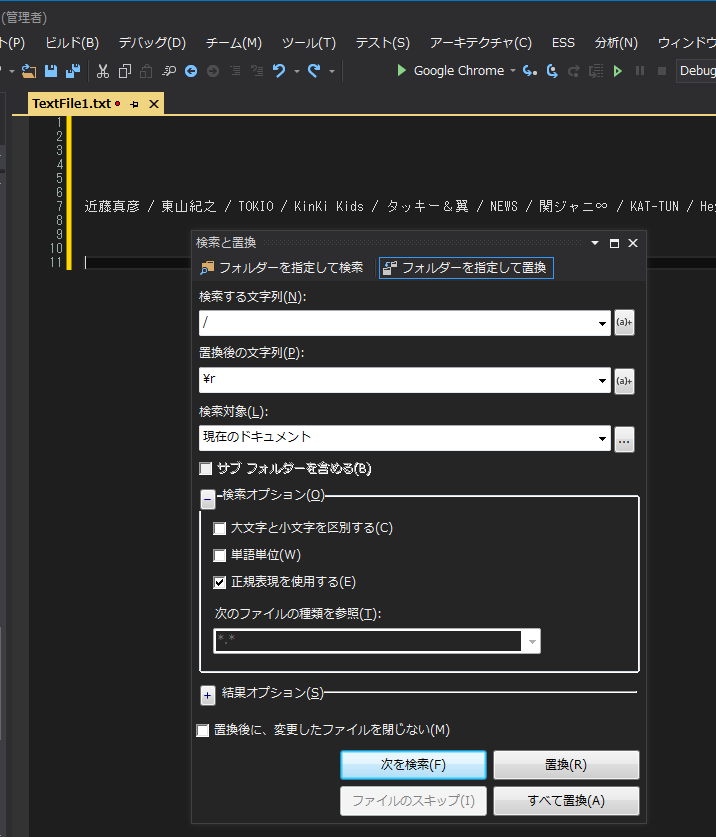
上記のように
検索する文字列 /
置換後の文字列 \r\n
検索対象 現在のドキュメント
と設定して、[すべて置換] ボタンを押すと一気に置換処理が実行される。
上の設定の意味は、正規表現を知らなくても大体分かると思う。
つまり、スラッシュ記号 / をWindowsの改行コード \r\n に置き換えるのだ。
ちなみに、改行コードは \n でも \r でも \r\n でもどれでも良い場合もあるが、OS環境やエディタ環境によって異なる場合があるので注意が必要だ。
実際、Windows上のVisual Studioの場合 \r に置き換えても、見た目は↓のように改行される。ところが、Windowsのメモ帳では、改行はあくまで \r\n なので \r で置換した結果をメモ帳に貼ると、↓のようにならずに一行に繋がった↑の状態の戻る。
さて、兎に角 スラッシュ / を改行コード \r\n に置換すると下図のようになる。
近藤真彦 東山紀之 TOKIO KinKi Kids タッキー&翼 NEWS 関ジャニ∞ KAT-TUN Hey! Say! JUMP(京セラドームより中継出演) Kis-My-Ft2 Sexy Zone A.B.C-Z 中山優馬 ジャニーズWEST
となる。
大体いい感じに出来たのだが、問題が有る。
スラッシュ / を改行に置換したので、スラッシュの前後に有った半角スペースが残っているのだ。
東山紀之
こんな感じ。
行頭を意味する^を覚える
では、これを取り除こう。
まずは名前の先頭の半角スペースを除去して、
東山紀之
にするのだ。実行結果は下図となる。
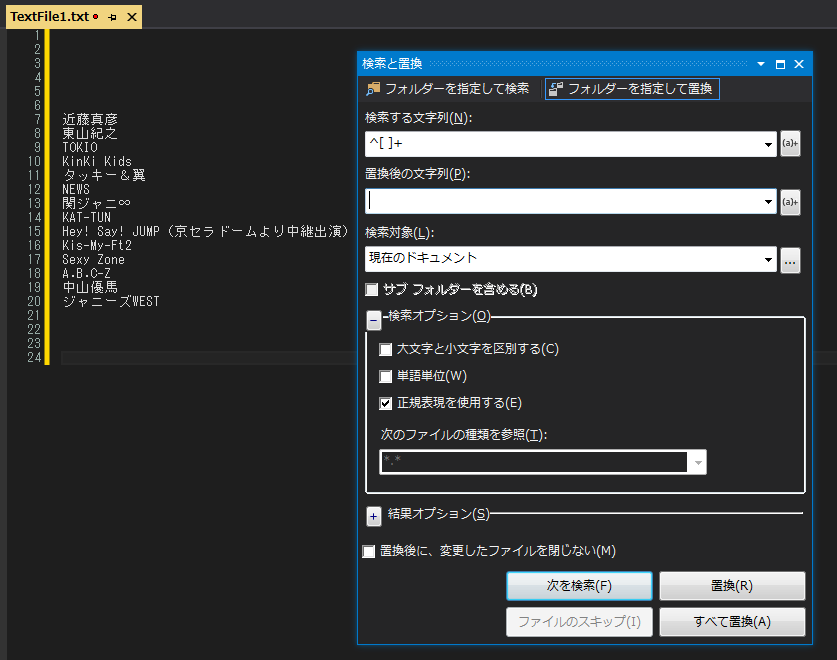
上記の置換コマンドは
検索する文字列 ^[ ]+ (カッコ内には半角スペースを1個書く)
置換後の文字列 (何も入れない。つまり空文字列)
と設定している。
ようやく正規表現っぽい記述が出てきた。
[] は[]内の1文字を意味する
ちなみに、
[a-z] と書けば a~z までの1文字を指す。
[a-zA-Z] と書けば アルファベットの大文字、小文字の1文字を指す。
[0-9a-zA-Z] と書けば 英数字の1文字を指す。
+ は、その直前の文字の1個以上の繰り返しを意味する。
* なら、その直前の文字の0個以上の繰り返しを意味する。
なので、
の意味は、
を意味するのだ。
つまり、
東山紀之
の先頭の 半角スペースにマッチするのだ。
なので、
東山紀之
のように複数個の半角スペースが有ってもマッチする。
それを置換後は空文字列に置き換えるので、
東山紀之
が得られるのだ。
では、もし全角スペースやタブが混じっている場合はどうするか?
全角SP半角SP全角SPタブ全角SP全角SPタブ東山紀之
こんな場合だ。
その時には、
^[半角SP全角SP\t]+
のように入力する
あるいは、空白文字を表す\sを使えばもっと簡単に書ける。
^[\s\t]+
これなら、先頭(^)に空白文字(\s)かタブ文字(\t)が一個以上ある(+)と言う意味になる。
\sと\tの順番は逆にして\t\sでも良い。
そうすると、半角SPか全角SPかタブ文字かのどれか一文字を指すのだ。
これで行頭の半角スペースが除去出来た。
行末を意味する$を覚える
最後に、行末の半角スペースを除去すれば完成だ。
行末は $ で表す。なので、皆さんはもうどう書けば良いか分かるはずだ。
正解は、
検索する文字列 [ ]+$ (カッコ内には半角スペースを1個書く)
置換後の文字列 (何も入れない。つまり空文字列)
となる。
ええっと、ここで問題が発生。通常はこれで良いのだが、例えばnotepad++ ではこれで期待通りに行末の空白が除去出来て、
東山紀之
が
東山紀之
となるのだ。
ところが Visual Studio ではそうならない。何故か?
この置換前の行は厳密に書くと、
東山紀之 \r\n
となっているのだ。
多くの場合、[半角SP]+$ で行末の半角SPの一個以上の繰り返しにマッチするのだが、Visual Studioの 場合にはこの \r\n も行末の直前にあると見なされるようだ。
なので、それらの改行コードも含めてやる必要があるようだ。
①検索する文字列 [ ]+[\r\n]+$
②置換後の文字列 \r
となる。ここまで読んだ人は、①の意味は大体理解できると思う。
半角SPの一個以上の繰り返しがあり、その直後に \r か \n の一個以上の繰り返しがあり、そして行末に達する部分文字列にマッチするのだ。
なので、
半角SP半角SP半角SP\r\r\n\n\r
などにもマッチする。
それを一個の改行コード \r に置き換える。
それを実行した結果が以下の通り。
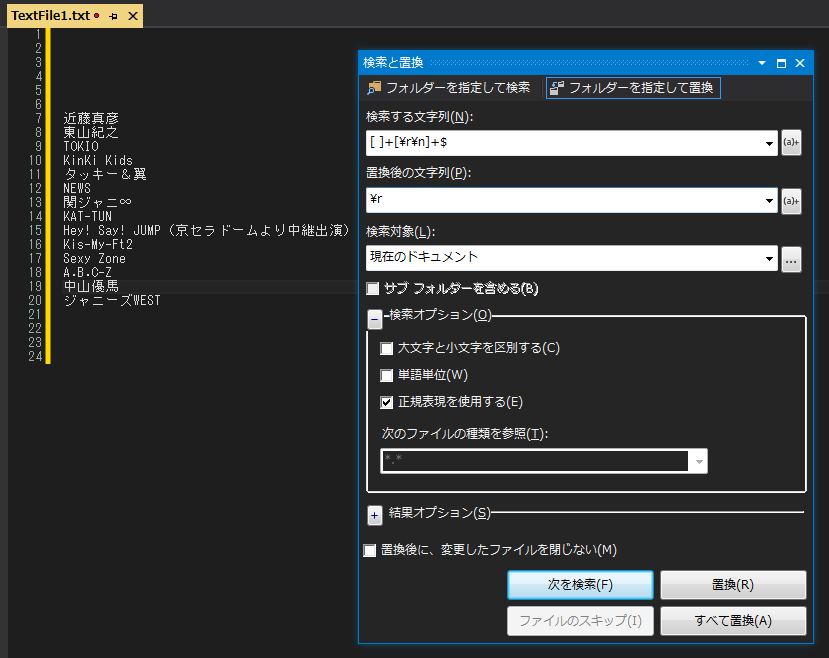
これで、各行の前後の空白が除去出来て、期待通りの結果が得られる。
このように、行末の改行コードの扱いに関しては、その正規表現の処理系の固有の挙動があるので注意が必要だが、そういう問題を自力で解決して行く過程でいろいろ学習できると思う。
もし一発のコマンドでやりたい場合は
①検索する文字列 [ ]+/[ ]+
②置換後の文字列 \r
と書けば良い。そうすると、冒頭の1行に名前が連なった行が、複数行に分離できて、かつ、名前の前後の半角スペースが除去できる。
ここまで読んだ皆さんなら、①の記述の意味は直ぐに理解できるだろう。
この表現を使うと、例えば
半角SP半角SP半角SP/半角SP半角SP半角SP 半角SP半角SP/半角SP 半角SP/半角SP
など、スラッシュ / の前後に1個以上の半角スペースがある部分文字列にマッチするのだ。
それを改行コードに置換する。
0個以上の繰り返しを意味する*を覚える
では、以下のように、/ の前後に半角スペースが有ったり無かったりと不規則な場合には↑の①の表現ではマッチしないものが出て来る。
下図のような状況だ。
近藤真彦/東山紀之 /TOKIO /KinKi Kids / タッキー&翼 /NEWS / 関ジャニ∞ / KAT-TUN / Hey! Say! JUMP(京セラドームより中継出演) / Kis-My-Ft2 / Sexy Zone / A.B.C-Z / 中山優馬 / ジャニーズWEST
この時には、
①検索する文字列 [ ]*/[ ]*
②置換後の文字列 \r
と書けば良い。
そうすると、スラッシュ / の前後に0個以上の半角スペースがあればマッチする。
なので、上記の+を使った例に加えて
半角SP半角SP/ /半角SP
にもマッチするのだ。
まとめ
正規表現入門の第一回目では、
^ 行頭を表す(^は別の意味で否定を意味する場合にも使われるので注意)
$ 行末を表す
+ 直前の文字の1個以上の繰り返し
* 直前の文字の0個以上の繰り返し
を覚える事が出来た。
補足
^を否定の意味で使う場合の例
[^a]+ aを含まない1文字以上の文字列(例: ‘0’ ‘123’ ‘ABC’ ‘bb’ … )
おまけ

ワテもその昔、読んだ記憶があるが528ページもある分厚いマニュアルのような本だ。
途中で挫折した事は言うまでも無い。
是非、皆さんも一冊買って、読破して頂きたい。
間違いなど有りましたらご指摘下さい。
一応、あと9回続く予定です。
こんな例が知りたいなどのご要望が有りましたらお知らせください。
お約束は出来ませんが、出来る範囲で努力します。

コメント