

ワテの場合、最近は時々Visual Studio 2017のC#を使ってデータベースを読み書きするプログラムを書いている。
世の中には沢山のDBシステムがあるが、ワテが主に使っているのは、
- Microsoft SQL Server 2016 Express(=MSSQL)
- MySQL
の二つだ。
WEBプログラミングの世界ではPHPやJavaScriptを使ってDBを操作する事は良くあるので、ネットにも沢山のサンプルがある。
一方、C#の場合でもネット検索するとPHPなどよりは少ないと思うがC#版のサンプルプログラムもあるので、ワテの場合はそういうサンプルをコピペして適当に組み合わせて勉強中だ。
なので、以下の例はあくまでDBに関して素人なワテの自己流のサンプルであるから、皆さんはまともな教科書を読んで頂くほうが良いかも。
さて、C#でDBを操作する場合には幾つかの方法があるが、最も単純な手法はDBを指定して文字列で作成したSQL文を実行するやり方だ。
ワテの理解ではSQL文と言えば、どんなDB(Oracle, MySQL, MSSQL, …)でも共通の文法だと思っていたのだが、その認識は違っていた。テーブルを作成(CREATE)したり、データを追加(INSERT)したり、そういう基本的な操作でも微妙にSQL文の表現が異なる場合がある事に気づいた。
良く忘れるのでワテの備忘録として本記事をまとめた。
- SQL Serverでテーブルを作成する
- その他のSQL文
- テーブルの削除 DROP
- テーブルのデータの削除 TRUNCATE
- テーブルの特定のデータの削除 DELETE
- SQL文の実行をやり直したい(UNDO)
- テーブルに新規カラムを追加する ALTER
- テーブルに新規カラムを追加する(自動採番にする) ALTER
- テーブルのカラムを指定してデータを追加する INSERT
- テーブルの名前を変える EXEC
- テーブルの特定カラム属性をヌル許容型に[設定/解除]する ALTER
- テーブルの特定のカラムにプライマリーキーを設定する ALTER
- SQL Server Management Studioでテーブルを操作しているとこんなメッセージが時々出る
- SELECTした列の値を変更する Replace
- SELECTした列の値を変更してテーブルも更新したい Replace
- カラムの中の数字を除去したい Replaceのネスト
- SELECTした列の値を変更する CONCAT
- SELECTした列の値を変更してテーブルも更新したい CONCAT
- 複数の列のデータを更新したい場合 Update
- 検索結果を並べ替える ORDER BY
- 二つの列のデータを入れ替えたい
- 二つのカラムを連結して新しいカラムに出力する
- まとめ
SQL Serverでテーブルを作成する
以下の関数はSQL Server 2016 Expressでデータベースにテーブルを新規に作成するための関数だ。
一応動くのだが、正統な手法なのかどうかはあまり自信はない。多分、これで良いと思うが。
void createTable()
{
// using System.Data.SqlClient; が必要
var dataSource1 = @".\SQLEXPRESS";
var dataSource2 = @"192.168.0.100,12345\SQLEXP2016X64";
var dataSource3 = @"(localdb)\v11.0";
var database = "MyTestDB"; // 事前に作成しておく必要あり。
var userid="sa";
var password = "ここにsaユーザーのパスワード文字列をセットする";
var connectionString = ""
+ "Data Source=" + dataSource3 + ";"
+ "Initial Catalog=" + database + ";"
+ "User id = " + userid + ";"
+ "password=" + password + ";";
var tableName = "TestTableName";
var cmdStr = "CREATE TABLE " + tableName
+ "([名前] nvarchar(50),\"住 所\" nvarchar(50),年齢 nvarchar(50));";
using (SqlConnection con = new SqlConnection(connectionString))
{
try
{
con.Open(); // Openは必要、closeは不要
using (SqlCommand command = new SqlCommand(cmdStr, con))
{
command.ExecuteNonQuery();
}
Debug.WriteLine("CreateTable成功 ->" + tableName + "<- 作成した。");
return;
}
catch (Exception ex)
{
Debug.WriteLine("何か例外発生したようだ。" + ex);
return;
}
}
}
ワテが理解出来ている範囲で処理の流れを説明すると、
データソースの選択
var dataSource1 = @".\SQLEXPRESS"; var dataSource2 = @"192.168.0.100,12345\SQLEXP2016X64"; var dataSource3 = @"(localdb)\v11.0";
データソースとは、DBの場所や種類を意味する。
ワテの場合、三種類のDBを使っている。
一番目は作業しているパソコンWin7にインストールしているSQL Server 2016 Express(32ビット)版のデータベースだ。
二番目は別のパソコン上で動いているSQL Server 2016 Express(64ビット)版のデータベースだ。IPアドレスの次にあるのがTCP/IPのポート番号で、確かデフォルトでは1433だったのだが、セキュリティ対策として別の番号に変えたと思う。それらの設定は確かSQL Server 2016構成マネージャでやった。その中でファイヤーウォールの設定でこのポートを有効化しておく必要がある。その辺りの設定は別の記事で詳しく書いているので参考にして頂きたい。
SQLEXPRESS, SQLEXP2016X64 などの名前はSQL Serverをインストールした時に自分で付けた名前だ。
三番目のDBは、SQL Server 2016 Express LocalDBと言うやつで、その名の通りローカル(今作業しているパソコン上)で動くDBだ。
だったら、一番目のDBと同じかなと思うが、確かにDBが動いているパソコンはどちらもローカルなパソコン上だ。LocalDBのメリットは、たとえばDBを使うアプリを配布する場合に、利用者のパソコンにSQL Serverがインストールされていなくても、LocalDB自身をアプリと一緒に配布出来るので、配布先でも簡単にDBを動かす事が出来る(らしい)。
データベースを作成する
"MyTestDB"
と言う名前のDBを事前に作成しておく。
DBの作成は簡単で、例えばSQL Server 2016 Management Studioを開けば、その中でDB作成を実行すれば簡単に出来る。名前を変更する事も簡単だ。削除も出来る。
もちろん、C#のプログラムでDB作成を行っても良いと思うが、ワテの場合その辺りは試していない。
接続のためのユーザーIDとパスワード
var userid="sa"; var password = "ここにsaユーザーのパスワード文字列をセットする";
SQL Server 2016 Expressをインストールすると、自動的に sa というアカウントが作成されていた。
「sa って一体誰やねん?」
「さ~」
ではなくて、System Administrator の略だ。SQL Server 認証用の管理者アカウントだ。まあ、Linux の root みたいなもんか(ワテの理解)。
パスワードもインストール時にセット出来る。インストール後でもManagement Studioで変更出来る。
これらの文字列を連結して、connectionStringを作成するとこんな感じ。
"Data Source=(localdb)\\v11.0;Initial Catalog=MyTestDB;User id=sa;password=*****;"
***** の部分にはsaのパスワード文字列をセットする。
ちなみに、DBに接続する場合の認証方式には、Windows認証というのとSQL Server認証というのがある(下図)。
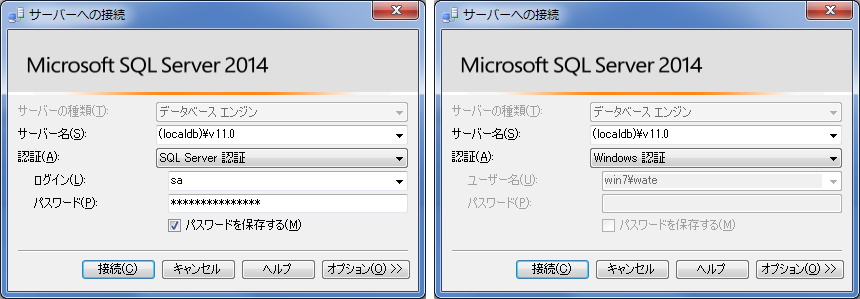
図 SQL Server認証画面とWindows認証画面の例
C#でプログラム的にDBに接続する場合にはこのSQL Server認証(左)の方式でやれば良いのだが、Windows認証(右)でも出来るのかどうかは未確認だ。でもまあ、SQL Server認証の方式で出来ているので、ワテの場合にはそれで十分なのだが。
SQL文
この例では、
| 列名 | データ型 |
| “名前” | nvarchar(50) |
| “住 所” | nvarchar(50) |
| “年齢” | nvarchar(50) |
こういう列を三つ持つテーブルを作成している。
列名に日本語を用いるのは良いのかどうかは知らないが、日本語でも問題は無いようだ。
以下に示すSQL文の文字列に、これらの列名を入れる場合には、
"CREATE TABLE TestTableName([名前] nvarchar(50),\"住 所\" nvarchar(50),年齢 nvarchar(50));"
ワテが試した限りでは、
[名前] \"住 所\" 年齢
のどの形式でも良いみたい。
つまり、文字列は間にスペースが無ければダブルクオーテーションで囲まなくても良い(三番目)。
でも、一般には [名前] のように角括弧で囲っておくと良いみたい。
あるいは、ダブルクオーテーションで囲って文字列風にしたい場合には、エスケープの円記号を組み合わせると良いみたいだ。
なので、最もスッキリした書き方はこんな感じかな。たぶん。
"CREATE TABLE TestTableName([名前] nvarchar(50),[住 所] nvarchar(50),[年齢] nvarchar(50));"
で、問題は、SQL文の初心者のワテの場合には、これらのSQL文をプログラムから実行し、いろいろ試してエラーするか正常終了するかどちらかで、そのSQL文が文法的に正しいかどうかが分かるが、それだと手間が掛かる。
もっと良い方法が無いかなあと考えて思いついたのは、SQL Server Management StudioでそのDBに接続しておいて、新しいクエリを開いてテストしたいSQL文を実行して、正常に実行されるかどうかで事前に正しいSQL文を調べておくと良いと思う(下図)。
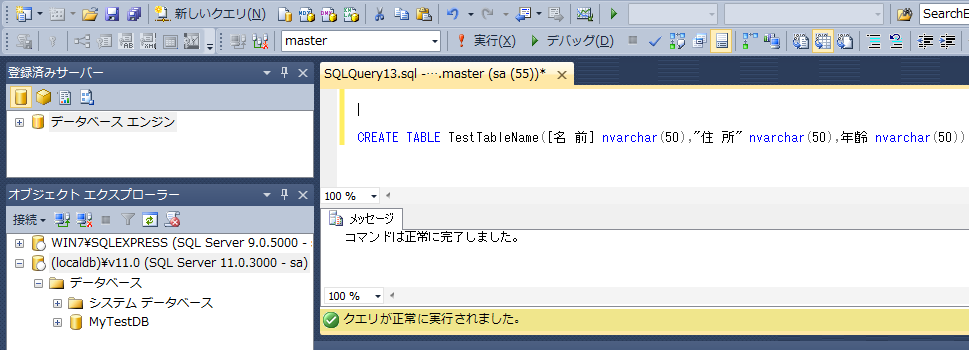
そうやって得られたSQL文の文字列をC#から実行すれば、一発で成功する。
なおMySQLの場合には、MySQL WorkbenchというSQL Server Management Studioに似た管理ツールがあるので、MySQL版の正しいSQL文を調べる場合にはMySQL Workbenchを使うと良い。
SQL文を実行する
using (SqlConnection con = new SqlConnection(connectionString))
{
try
{
con.Open(); // Openは必要、closeは不要
using (SqlCommand command = new SqlCommand(cmdStr, con))
{
command.ExecuteNonQuery();
}
Debug.WriteLine("CreateTable成功:" + tableName + "を作成した。");
return;
}
catch (Exception ex)
{
Debug.WriteLine("何か例外発生したようだ。" + ex);
return;
}
}
C#の場合、usingの構文を使うと new で作成したインスタンスを自分でDisposeしなくても関数を抜ける時に自動的にやってくれるので便利だ。
ここでは二つのusingを使っている。
この辺りの構文もネット上のサンプルを適当に組み合わせて自作したので、たぶんこれで良いと思うが、正しい文法はちゃんとした教科書を読んで頂くほうが良いかも。
最初のusingでconnectionStringを使ってDBに接続する為の接続用オブジェクトを作成する。
二番目のusingで、コマンドオブジェクト(command)を作成する。
このように作成したコマンドオブジェクト(command)を使って、
command.ExecuteNonQuery(); command.ExecuteReader(); command.ExecuteScalar(); その他いろいろ
のメソッドを実行出来る。
SQL文を実行してその結果のデータを取得する場合には、ExecuteReader()を使うのだが、今の場合にはテーブルを作成(CREATE)するだけなので、ExecuteNonQuery()を使う。同様に、UPDATE、INSERT、DELETEなどを実行する場合にもExecuteNonQuery()を使う。
なおデータベースがMySQLの場合にも、上記の構文と非常に良く似た形式で書く事が出来て、MSSQLの場合の以下の三つの行を
using System.Data.SqlClient;
using (SqlConnection con = new SqlConnection(connectionString))
using (SqlCommand command = new SqlCommand(cmdStr, con))
MySQLの場合なら、以下のように書き換えると
using MySql.Data.MySqlClient;
using (MySqlConnection con = new MySqlConnection(connectionString))
using (MySqlCommand command = new MySqlCommand(cmdStr, con))
MSSQLでもMySQLでも同じ形式
command.ExecuteNonQuery();
でコマンドを実行出来るのでMSSQL版関数からMySQL版関数を作成するのは簡単だ。
つまりMyを頭に付ければ良い。
とは言っても、この規則がいつでも成り立つ訳ではなくて、CREATE TABLEなどの基本的なコマンドなら同じになるが、例えばExecuteReader()でデータを読み出す場合ではMSSQLとMySQLとでは、二番目のusingの{…}内でデータを読み出す部分の構文が若干異なる場合もあるので注意が必要だ。ワテも全部は試していないのであまり詳しくは説明出来ない。
その他のSQL文
テーブルの削除 DROP
DROP TABLE [MyTestDB].[dbo].[TestTableName]
今作成したテーブルTestTableNameを削除したい場合はこれで行ける。
テーブルのデータの削除 TRUNCATE
TRUNCATE TABLE [MyTestDB].[dbo].[TestTableName];
テーブルは消さずに、テーブルの中身を空にしたい場合はTRUNCATEだ。
テーブルの特定のデータの削除 DELETE
DELETE FROM [MyTestDB].[dbo].[TestTableName] WHERE [名前] IS NULL
TestTableNameのデータのうち、[名前]カラムがNULLのものを削除したい場合はこれで行けた。
SQL文の実行をやり直したい(UNDO)
テーブルの削除、テーブル内のデータの変更など、SQL文を実行すると一瞬で完了してしまう。
うっかり間違ったSQL文を発行してしまい、全部のデータがパーになってしまう恐れもある。
そんな時に、SQL文を取り消す事が可能なのだ。
BEGIN TRANSACTION; delete FROM [TableName] where [name] is null ROLLBACK TRANSACTION;
SQLの実行を取り消す事が出来る
要点としては、SQL文の実行前に
BEGIN TRANSACTION;
を実行しておく。
そしてSQL文を実行。
それを取り消したい場合には、
ROLLBACK TRANSACTION;
を実行すれば良い。
テーブルに新規カラムを追加する ALTER
ALTER TABLE [dbo].[CompanyTable] ADD id int not NULL;
idと言う名前のカラムをint型で追加。NULLは許容しない。
テーブルに新規カラムを追加する(自動採番にする) ALTER
ALTER TABLE [dbo].[CompanyTable] add Id2 int IDENTITY(1, 1);
IDENTITYという属性を追加すると、自動で連番が付けられるらしい。自動インクリメント列とか自動採番などという用語で呼ばれるようだ。
なお、既存のカラムを
ALTER TABLE テーブル名 alter column;
を実行して、IDENTITY属性を後から付加する事は出来ないらしい。MSDNのフォーラムにも回答があった。
その場合は新規にテーブルを作り直すか、あるいはテーブルはそのままで新規にIDENTITY属性を持つカラムを追加して、古いカラムは削除するなどで対処するらしい。
テーブルのカラムを指定してデータを追加する INSERT
INSERT INTO [dbo].[TestTableName] ([id], [name]) VALUES('12345', 'wareko');
複数のデータを追加するならこんな感じ。
INSERT INTO [dbo].[TestTableName] ([id], [name])
VALUES('12345', 'wareko'), ('67890', 'wareko2');
テーブルの名前を変える EXEC
EXEC sp_rename 'TestTableName', 'TestTableName_001'
これで名前を変える事が出来た。これで良いのかな?
テーブルの特定カラム属性をヌル許容型に[設定/解除]する ALTER
alter table [dbo].[TestTableName] alter column id nvarchar(40) null alter table [dbo].[TestTableName] alter column id nvarchar(40) not null
これで出来た。
テーブルの特定のカラムにプライマリーキーを設定する ALTER
ALTER TABLE [dbo].[TestTableName] ADD PRIMARY KEY (id)
SQL Server Management Studioでテーブルを操作しているとこんなメッセージが時々出る
変更の保存が許可されていません。行った変更には、次のテーブルを削除して再作成することが必要になります。再作成できないテーブルに変更を行ったか、テーブルの再作成を必要とする変更を保存できないようにするオプションが有効になっています。
何だか英文メッセージを直訳した感じの良く分からない日本語だ。
兎に角、DBの設定において、
テーブルの再作成を必要とする変更を保存できないようにする 有効
という設定がデフォルトでは有効化されているようだ。
例えば、既存のカラムに対してNULL許容属性をONやOFFに変更しようとするとこういうメッセージが出た。
そういう場合には、SQL文を実行すれば変更が出来る。
alter table [dbo].[TestTableName] alter column id nvarchar(40) not null
でも面倒なので、上記のオプションを無効化してしまえば良いのではと思ったのだが、MSDNのこの説明によると、それはお勧めでは無いらしい。
重要 [テーブルの再作成を必要とする変更を保存できないようにする] オプションを無効にすることでこの問題を回避することはお勧めしません。このオプションを無効にするリスクの詳細については、「詳細」を参照してください。
詳細に関しては、上記のMSDNのリンクを開くと長々と解説があるのだがSQL初心者のワテには良く分からん。まあ、alter table でやれば良いと言う事を覚えておけば良いだろう。
SELECTした列の値を変更する Replace
例えばテーブルに幾つかの列があり、その中のColName1という列の値に★が入っているものがある。その中で先頭に★があるもののみ★を取り除きたい。
実行前 実行後 +-----------+---------------------------+ | ColName1 | REPLACE(ConName1,'★','') | +-----------+---------------------------+ | ★大阪 | 大阪 | | ★東京 | 東京 | | 京都★ | 京都★ | +-----------+---------------------------+
実行前後のテーブルの状態1
そのSQL文
SELECT [ColName1], REPLACE([ColName1],'★','') FROM [dbo].[TableName] where [ColName1] like '★%';
これで大阪と東京の★が無くなる(実行前後のテーブルの状態1)。
この場合、SELECTしているだけなのでテーブルTableNameの中身は変わらない。
Replaceの文法は以下の通り。
SELECT REPLACE(列名, '置換対象文字', '置換後文字') FROM [テーブル名] Where 条件
SELECTした列の値を変更してテーブルも更新したい Replace
もしテーブルの値を変更したい場合はUpdate文で可能だ。
Update [dbo].[TableName] Set [ColName1] = REPLACE([ColName1],'★','') where [ColName1] like '★%';
これを実行すると ColName1の列のみ先頭の★が取り除かれる。テーブルに他の列 ColName2, ColName3, … などが有ってもそれらの値は変更されない。
カラムの中の数字を除去したい Replaceのネスト
例えば [ID], [FirstName], [LastName] と言う三つのカラムを持つテーブルに人名を保管した。
ところがデータをInsertする時にうっかり間違えて、名前の前にID番号をくっ付けてしまった。
| ID | LastName | FirstName |
| 1 | 小池 | 1百合子 |
| 2 | 田中 | 2角栄 |
| 3 | ワレコ | 3ワレコ |
| 4 | ケネディ | 4ジョン・フィッツジェラルド・”ジャック” |
| 5 | 本田 | 5真凜 |
| … | … | … |
この名前の前の数字を除去するSQLはこんな感じか。
Update [dbo].[Person] Set [FirstName]= REPLACE (REPLACE (REPLACE (REPLACE (REPLACE (REPLACE (REPLACE (REPLACE (REPLACE (REPLACE ([FirstName], '0', ''), '1', ''), '2', ''), '3', ''), '4', ''), '5', ''), '6', ''), '7', ''), '8', ''), '9', '') -- where ID >10 -- 必要なら条件を指定する
まあ、単にReplace関数を入れ子にして0~9までのどの数字でも除去すると言うやり方だ。
SQL文ではいわゆる正規表現は使えないようなので、こんなヘンテコ作戦でやった。
もっとスマートな方法は無いのかな?
SELECTした列の値を変更する CONCAT
Replaceとよく似たConcatだ。この場合は文字列を連結出来る。
実行前 実行後
+-----------+---------------------------+
| SiteName | CONCAT('NHK',[SiteName]) |
+-----------+---------------------------+
| 社会 | NHK社会 |
| 政治 | NHK政治 |
| 経済 | NHK経済 |
+-----------+---------------------------+
以下のSQLを実行すると、TableNameテーブルの中でCategoryが’NHKニュース’に一致する行のみが取り出せて、その中の[SiteName]列の文字列データの先頭に’NHK’という文字を結合出来る。
SELECT [SiteName], CONCAT('NHK',[SiteName])
FROM [dbo].[TableName]
where [Category] = 'NHKニュース';
これを実行してもテーブルの中身は変更されない。
SELECTした列の値を変更してテーブルも更新したい CONCAT
変更したい場合は、以下のSQLで可能だ。
Update [dbo].[TableName]
Set [SiteName] = CONCAT('NHK',[SiteName])
where [Category] = 'NHKニュース';
このように、ワテの場合はSQL初心者なので、まずはUpdateをしないバージョンを実行して、その出力結果を確認する。
それで良ければUpdate文に書き換えて実行している。
SQL文は一瞬に実行されるので、もし間違えていると一瞬にしてデータがパーになる。
その場合に、やり直す方法があるのかどうかは良く知らない。今後、調査したい。
複数の列のデータを更新したい場合 Update
Update [dbo].[TableName] Set [ColName1] = N'新しい値1', [ColName2] = N'新しい値2', [ColName3] = N'新しい値3' where [Category] = 'NHKニュース';
このように変更したい列名と値を Set 以降にズラズラと並べれば良い。このSetの所に登場しない列に関しては値は変化しない。
なお、SQL Serverの文字列型の列にデータを書き込む場合には、先頭に ‘N’ を付けておくと良い。これが無いと文字が化ける。詳細は別の記事で紹介予定だ。
検索結果を並べ替える ORDER BY
SELECT * FROM [dbo].[TableName] ORDER BY [ColName1] ASC, [ColName2] DESC, [ColName3] ;
ASC 昇順 1,2,3, … 増える方向
DESC 降順 9,8,7, … 減る方向
に並び替えられる。省略時はASCの動作となる。
二つの列のデータを入れ替えたい
例えば [ID], [FirstName], [LastName] と言う三つのカラムを持つテーブルに人名を保管した。
ところが、姓と名を逆に入れてしまった。
例えば小池百合子さんなら、正しくは
百合子 FirstName これが正解 小池 LastName これが正解
と入力すべきところを、苗字と名前を逆に入力してしまったとする。
小池 FirstName これは間違い 百合子 LastName これは間違い
これを入れ替えて正しく修正するSQLはこんな感じで出来た。
DECLARE @tempcol as nvarchar(max) update [dbo].[Person] set @tempcol= [FirstName], [FirstName]= [LastName], [LastName]= @tempcol where [ID] = 6; -- 小池百合子さんのID
なお、ワテの場合、日常生活でも First Name と Last Name がどっちがどっちなのか良く忘れる。
覚え方としては、
Hi, Yuriko!
と言う感じで、最初に呼ばれる名前が First Nameだ。
二つのカラムを連結して新しいカラムに出力する
例えばテーブルに
[店名] [住所]
と言う二つのカラムがある。
それを使って
[店名] [住所] [店名住所]
と言う三つのカラムに出力する。
かつ、新しく生成する[店名住所]カラムに入れるデータは、[店名]と[住所]を単純に連結するのではなくて、改行コードを入れる。
つまり二行に渡るデータを入れるのだ。
そのSQL文はこんな感じで良いのかな?
SELECT [店名], CONCAT([店名], NCHAR(13) + NCHAR(10), [住所]) as [店名住所], [住所], FROM [database_name].[dbo].[table_name];
SQL サーバーの場合、改行コードは四種類ある。
CR(キャリッジリターン) CHAR(13)、NCHAR(13) LF(ラインフィード) CHAR(10)、NCHAR(10)
ワテの場合は、文字列型のカラムはNVARCHAR型にしているので、NCHAR(13)やNCHAR(10)を使った。
ワテの理解では、
NVARCHAR、NCHAR Unicode 対応(全角文字を保管する場合)
VARCHAR、CHAR ASCII 対応(半角の英数字記号を保管する場合)
だ。
VARが付くと可変長、VAR無しは固定長だ。
半角の英数字しか使わないので有れば、CHAR(10)、CHAR(13)で良いだろう。
まとめ
SQL文は沢山の構文があるので、マスターするのはなかなか難しい。
上記の例は、SQL初心者のワテがネット上のサンプルを適当に組み合わせて実験したものなので、正統的な手法かどうかは未確認。
でも、まあ動くのでそんなにはおかしくないと思うが。
みなさんは良い教科書を読むのが良い。


この本はお勧めだ。
著者の松本美穂さんと松本崇博さんは夫婦のようで、夫婦でMicrosoft SQL Serverのコンサルティングやトレーニングなどを行う会社を経営されている。

会社概要を引用させて頂くと
- SQL Server コンサルティング サービス
- SQL Server メンタリング サービス(運用管理支援)
- SQL Server と .NET を中心としたトレーニングの企画、実施
- データベース関連トレーニング テキスト及びマニュアルの作成、監修
なので、SQL Serverの伝道師と言っても良いだろう。
同じ著者で、これもお勧めだ。


ワテも読んだが、SQLサーバーを勉強するには最適の教科書だ。
これら以外の、
松本美穂 松本崇博
さんの著作を探す。

コメント